Архитектуры нейронных сетей
Различные структуры для решения различных задач машинного обучения
Полносвязные сети
Полносвязные нейронные сети (Fully Connected Networks) — это базовый тип архитектуры, где каждый нейрон одного слоя соединен со всеми нейронами следующего слоя.
Полносвязные сети, также известные как многослойные перцептроны (MLP), являются основой многих нейронных сетей. Они состоят из входного слоя, одного или нескольких скрытых слоев и выходного слоя. Каждый нейрон в слое получает входы от всех нейронов предыдущего слоя.
Эти сети хорошо подходят для задач классификации и регрессии, где входные данные представлены в виде векторов признаков. Однако для данных с пространственной структурой, таких как изображения, полносвязные сети могут быть неэффективными из-за большого количества параметров.
Основное преимущество полносвязных сетей — их универсальность и способность аппроксимировать любую непрерывную функцию при достаточном количестве нейронов. Они часто используются в качестве финальных слоев в более сложных архитектурах для выполнения классификации или регрессии на основе извлеченных признаков.
Сверточные нейронные сети
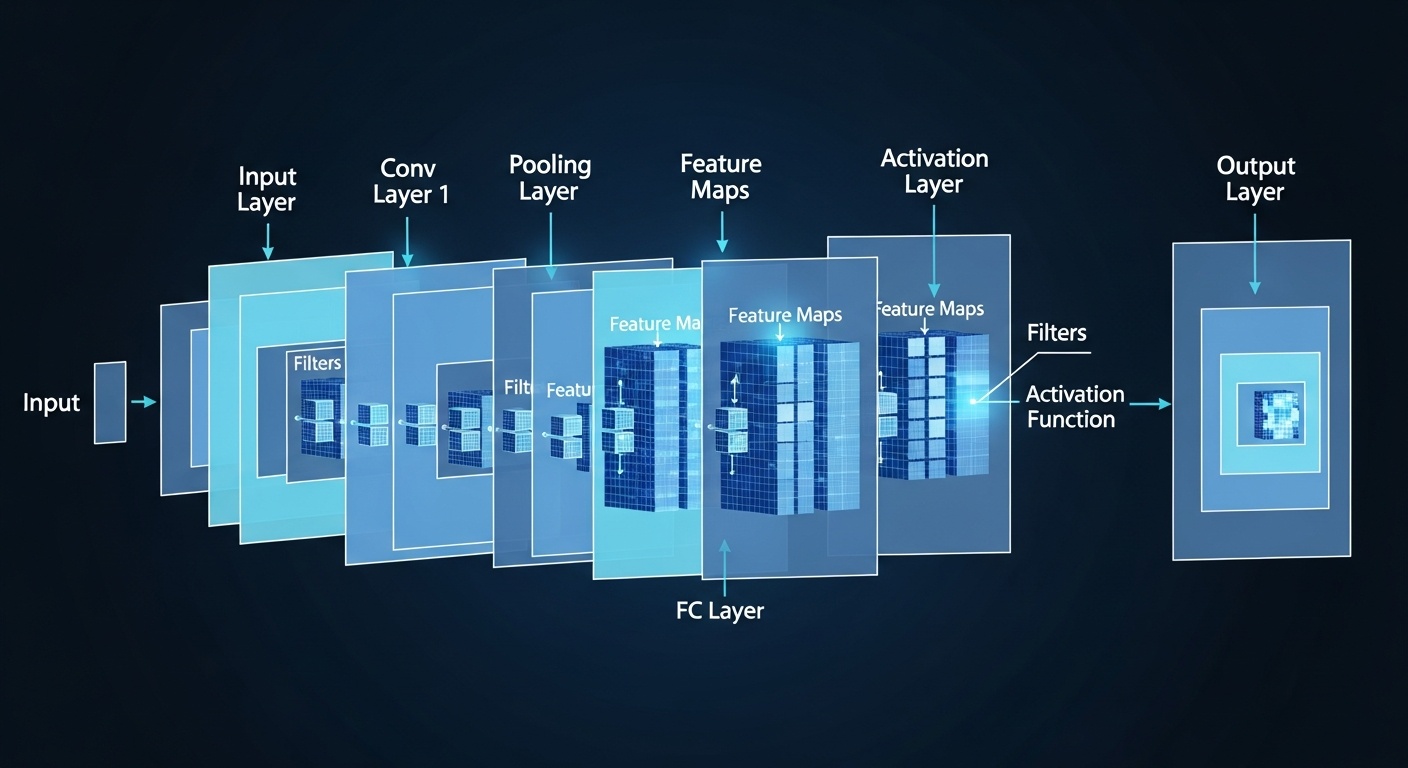
CNN для обработки изображений
Сверточные нейронные сети (CNN) специально разработаны для обработки данных с сеточной структурой, таких как изображения. Они используют сверточные слои, которые применяют фильтры к небольшим областям входных данных, что позволяет сети обнаруживать локальные признаки.
Ключевые компоненты CNN включают сверточные слои для извлечения признаков, слои пулинга для уменьшения размерности и полносвязные слои для финальной классификации. Эта архитектура эффективно использует пространственную структуру данных и значительно сокращает количество параметров по сравнению с полносвязными сетями.
CNN революционизировали область компьютерного зрения и достигли выдающихся результатов в задачах распознавания изображений, обнаружения объектов и сегментации. Современные архитектуры, такие как ResNet, VGG и Inception, используют различные техники для улучшения производительности и обучения более глубоких сетей.
Рекуррентные нейронные сети
Рекуррентные нейронные сети (RNN) предназначены для обработки последовательностей данных, где порядок элементов имеет значение.
RNN имеют циклы в своей структуре, что позволяет им сохранять информацию о предыдущих элементах последовательности. Это делает их идеальными для задач обработки естественного языка, распознавания речи и анализа временных рядов.
Однако стандартные RNN страдают от проблемы затухающих градиентов при обучении на длинных последовательностях. Это привело к разработке более сложных архитектур, таких как LSTM (Long Short-Term Memory) и GRU (Gated Recurrent Unit), которые используют механизмы ворот для контроля потока информации и лучше справляются с долгосрочными зависимостями.
LSTM и GRU сети стали стандартом для многих задач обработки последовательностей, включая машинный перевод, генерацию текста и анализ тональности. Они способны запоминать информацию на протяжении длительных периодов и эффективно обрабатывать последовательности различной длины.
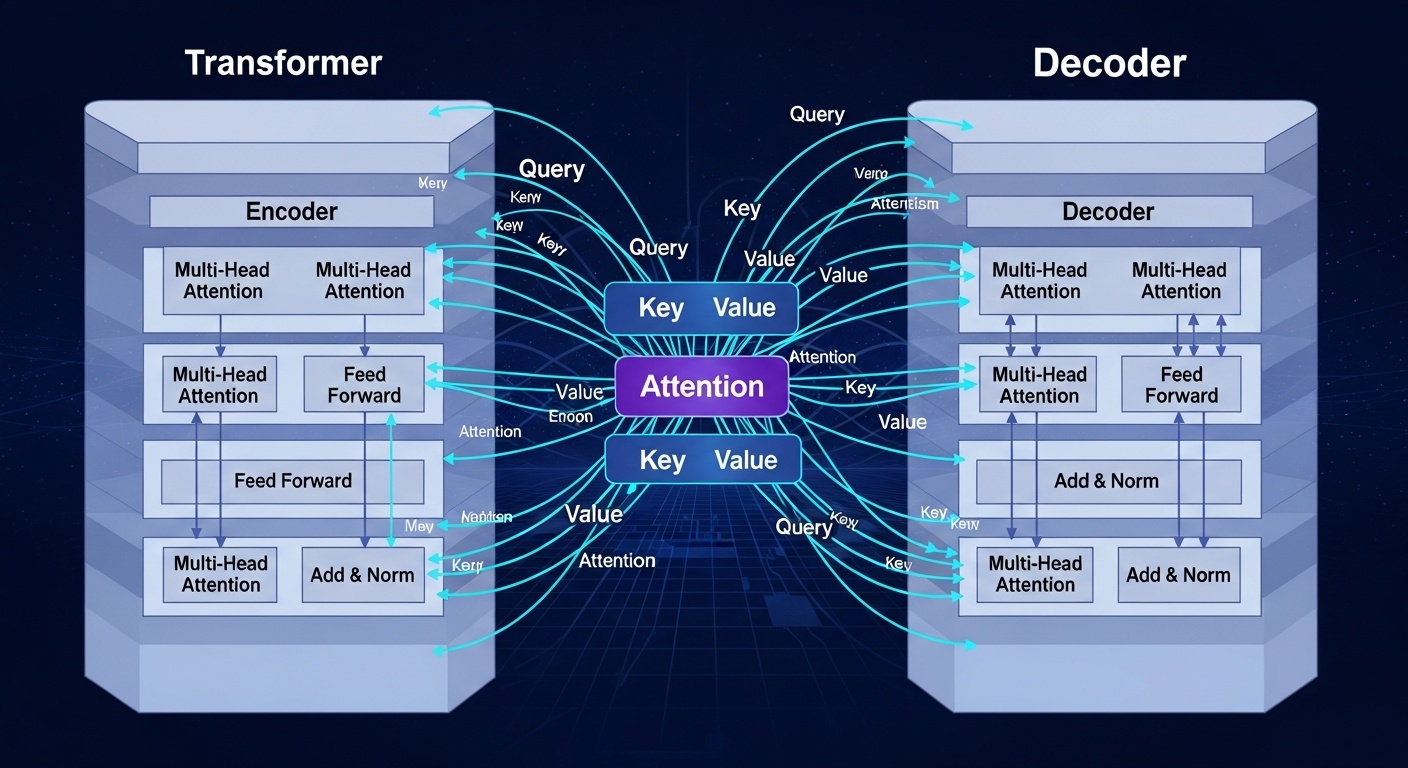
Трансформеры
Архитектура внимания
Трансформеры — это революционная архитектура, основанная на механизме внимания (attention mechanism). В отличие от RNN, трансформеры обрабатывают всю последовательность параллельно, что делает их обучение значительно быстрее.
Ключевой компонент трансформеров — механизм самовнимания (self-attention), который позволяет модели взвешивать важность различных частей входной последовательности при обработке каждого элемента. Это позволяет модели эффективно моделировать долгосрочные зависимости без необходимости последовательной обработки.
Трансформеры произвели революцию в области обработки естественного языка и привели к созданию таких моделей, как BERT, GPT и T5. Эти модели достигли выдающихся результатов в широком спектре задач NLP и стали основой для многих современных приложений искусственного интеллекта.